过滑块可以注册出did,但是did的可用性完全不能符合预期。
为了分析具体原因,笔者对web端验证流程进行了分析和测试。

验证流程
【温馨提示:此处隐藏内容需要付费订阅后才能查看!】
测试情况
【温馨提示:此处隐藏内容需要付费订阅后才能查看!】
所以采集上量需要将整个流程(1-7)实现。
log参数
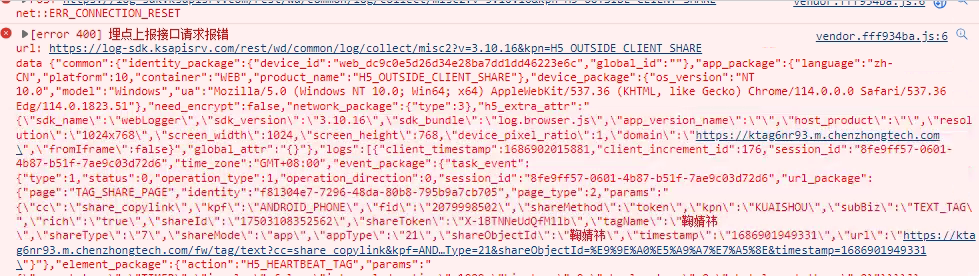
为了确定日志中是否有参数和IP绑定,检查了session_id参数。
session_id

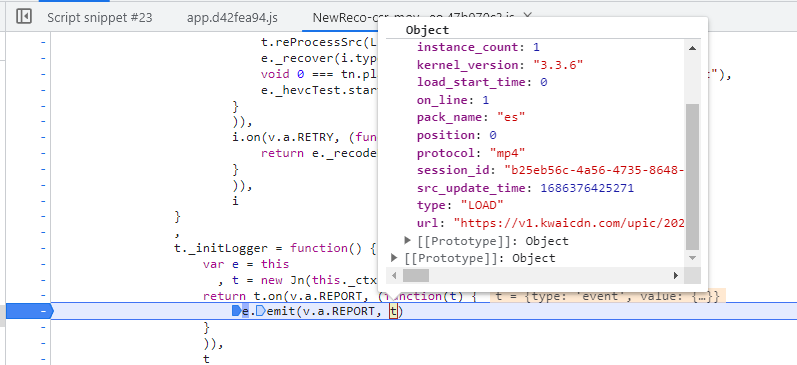
session_id
i = (wn[e[t + 0]] + wn[e[t + 1]] + wn[e[t + 2]] + wn[e[t + 3]] + "-" + wn[e[t + 4]] + wn[e[t + 5]] + "-" + wn[e[t + 6]] + wn[e[t + 7]] + "-" + wn[e[t + 8]] + wn[e[t + 9]] + "-" + wn[e[t + 10]] + wn[e[t + 11]] + wn[e[t + 12]] + wn[e[t + 13]] + wn[e[t + 14]] + wn[e[t + 15]]).toLowerCase();生成
const crypto = require('crypto');
function Ln() {
var Cn = new Uint8Array(16);
return getRandomValues(Cn)
}
function getRandomValues(arr) {
if (!(arr instanceof Uint8Array)) {
throw new TypeError("Argument should be a Uint8Array");
}
crypto.randomFillSync(arr);
return arr;
}
for (var Rn = /^(?:[0-9a-f]{8}-[0-9a-f]{4}-[1-5][0-9a-f]{3}-[89ab][0-9a-f]{3}-[0-9a-f]{12}|00000000-0000-0000-0000-000000000000)$/i,
Dn = function(e) {
return "string" == typeof e && Rn.test(e)
},
wn = [], In = 0; In < 256; ++In
)
wn.push((In + 256).toString(16).substr(1));
function MN(e, t, i) {
var n = (e = e || {}).random || (e.rng || Ln)();
if (n[6] = 15 & n[6] | 64,
n[8] = 63 & n[8] | 128,
t) {
i = i || 0;
for (var r = 0; r < 16; ++r)
t[i + r] = n[r];
return t
}
return Nn(n)
}
function Nn(e) {
var t = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : 0
, i = (wn[e[t + 0]] + wn[e[t + 1]] + wn[e[t + 2]] + wn[e[t + 3]] + "-" + wn[e[t + 4]] + wn[e[t + 5]] + "-" + wn[e[t + 6]] + wn[e[t + 7]] + "-" + wn[e[t + 8]] + wn[e[t + 9]] + "-" + wn[e[t + 10]] + wn[e[t + 11]] + wn[e[t + 12]] + wn[e[t + 13]] + wn[e[t + 14]] + wn[e[t + 15]]).toLowerCase();
if (!Dn(i))
throw TypeError("Stringified UUID is invalid");
return i
}
console.log(MN({},undefined,undefined))session_id 只是普通的uuid
identity
identity也是uuid,需要注意中间的4。
function F() {
return "xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx".replace(/[xy]/g, (function(t) {
var e = 16 * Math.random() | 0;
return ("x" == t ? e : 3 & e | 8).toString(16)
}
))
}project_id
没仔细看,new-reco页面定值76d8154812
这三个用python还原下。
import os
import random
project_id = "76d8154812"
def generate_identity():
uuid_template = "xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx"
uuid = ""
for char in uuid_template:
if char == "x":
uuid += format(random.randint(0, 15), "x")
elif char == "y":
uuid += format(random.randint(8, 11), "x")
else:
uuid += char
return uuid
def generate_session_id(t=None, i=0):
n = bytearray(os.urandom(16))
t = t or bytearray(16)
n[6] = 15 & n[6] | 64
n[8] = 63 & n[8] | 128
for r in range(16):
t[i + r] = n[r]
i = "".join([("%02x" % x) for x in t])
i = i[:8] + "-" + i[8:12] + "-" + i[12:16] + "-" + i[16:20] + "-" + i[20:]
return i流程1-4
在 gdfp.gifshow.com/p/z/s 找到了上传IP和指纹的信息。比较符合流程3的判定。
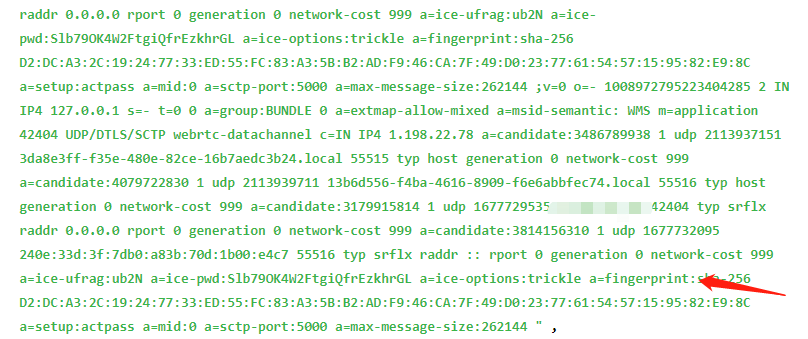
看起来是一个网络传输协议中的候选者信息,每个分号后面的部分都表示一个具体的候选者的属性信息。
其中包括了IP地址、端口、类型等信息。这些信息在网络通信中用于选择最佳的通信路径。候选者信息是使用SDP协议的语法进行编码的,每个候选者信息是一个SDP媒体描述符,并且它们使用分号来分隔。每一个分号后面的部分都代表了媒体描述符的各个属性。在这些候选者信息中,常用属性包括:
candidate: \
其中:
foundation 是一个字符串,表示候选者的基础属性;
component-id 是这个部分的ID,通常是 1;
transport 是协议类型,常见的有 udp 和 tcp;
priority 代表优先级;
connection-address 和 port 是地址和端口信息;
typ 表示候选者的类型,包括 host、srflx 和 relay 等;
raddr 和 rport 表示候选者反射后的地址和端口号,用于服务器反射类型的候选者。
所以这两则日志比较关键,bussType是com.vision.gifshow 和 manMachine。man Machine 翻译过来就是人机。
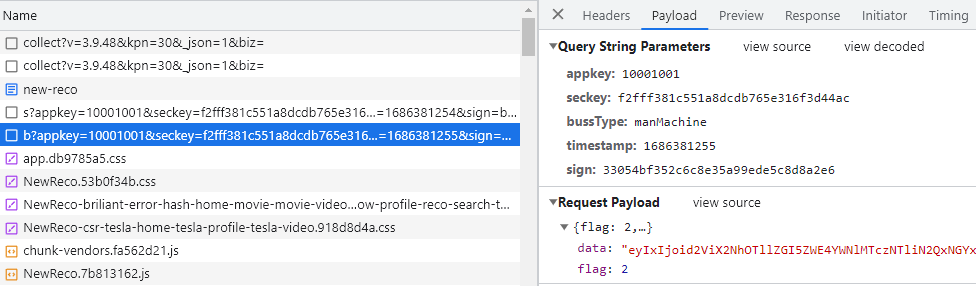
接下来构建流程1-4,尝试是否能完成。
请求参数sign
sign = Y(i + o + a)

from lxpy import get_md5
def get_sign():
appKey = "10001001"
timestamp = int(time.time())
seckey = "f2fff381c551a8dcdb765e316f3d44ac"
return get_md5(appKey+seckey+str(timestamp))appKey 和seckey 固定。
日志formdata
base64解码可以看到data明文。
参数太多了,除了session_id、多个identity,还有一堆指纹、时间、候选者信息。
82
日志中 82 的这些pc、ph、wf、wh、cf、ch、mf之类又和滑块验证时的设备指纹不同。
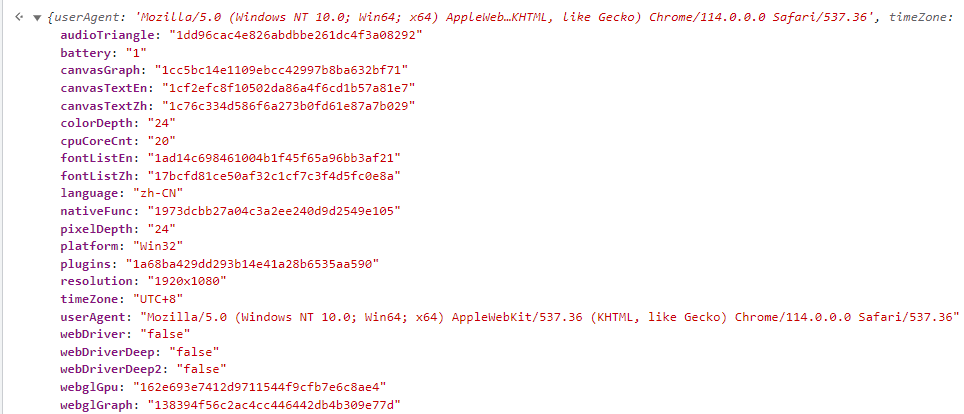
看起来像是一个包含了不同维度的浏览器元素信息。
pc: 页面缩放比例(单位%)
ph: 浏览器边框的哈希值
wf: 文档可视宽度
wh: 文档可视高度的哈希值
cf: 容器的宽度
ch: 容器的高度的哈希值
mf: 元素的宽度
mh: 元素的高度的哈希值
ff: 字体大小
fh: 字体的哈希值
af: 元素的绝对宽度
ah: 元素的绝对高度的哈希值
gr: 元素的相对宽度
gh: 元素的相对高度的哈希值
el: 文档的字体大小
eh: 文档的字体的哈希值
ow: 窗口的宽度
oh: 窗口的高度的哈希值
ky: 计算元素所用的比例
kh: 计算元素所用的比例的哈希值
ci: 元素的内容宽度
ih: 元素的内容高度的哈希值。
都是猜的我也不确定,一般通过这些参数能更好地了解用户环境和行为。
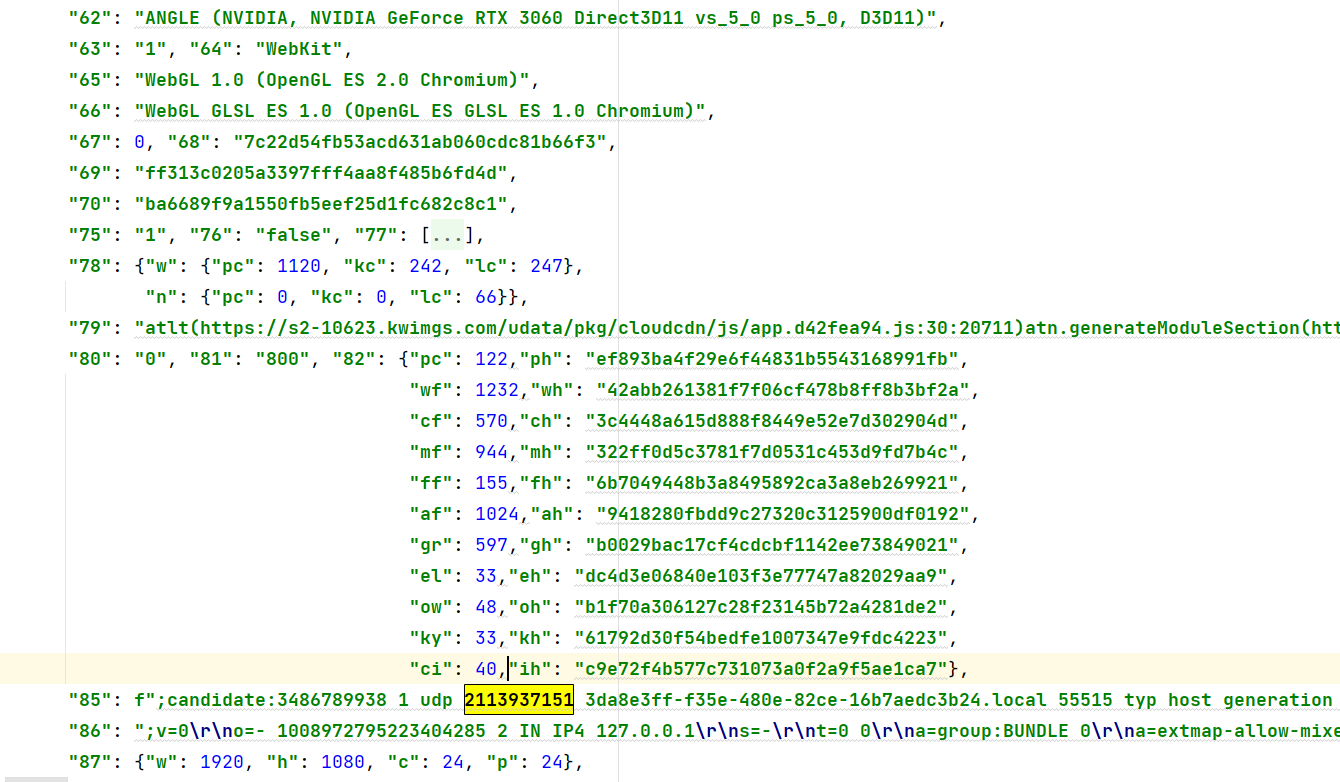
85
85是前面提到的网络传输协议中的候选者信息,包含了用户当前IP。
86
86是一个实时通信协议WebRTC的SDP请求的信息。其中了包含以下信息:
v=0: SDP协议版本
o=- 1008972795223404285 2 IN IP4 127.0.0.1: 连接的会话信息(包括源地址、会话ID、版本号、网络地址等)
s=-: 会话名称
t=0 0: 会话起始时间和结束时间
a=group:BUNDLE 0: 分组信息,此处表示聚合了一个流
a=extmap-allow-mixed: 扩展映射
a=msid-semantic: WMS:媒体流标识符语义
m=application 9 UDP/DTLS/SCTP webrtc-datachannel: 媒体流描述(应用程序数据和Webrtc数据通道)
c=IN IP4 0.0.0.0: IP网络连接地址
a=candidate:…: ICE候选地址信息
a=fingerprint:…: DTLS摘要指纹
a=setup:…: 安装过程
a=mid:0:媒体流ID
a=sctp-port:5000:SCTP传输控制协议端口
a=max-message-size:262144: 数据最大消息大小限制
c=IN IP4 {IP}: IP网络连接地址
日志中要看的参数太多了,我的建议是放弃分析。大家可以简单构建一下请求,看看缘分吧。
流程5-7
流程5-7不写了,之前写了很多版的滑块文章,大家自己在博客找找。
需要注意的是在接口中获取captcha_session,验证后携带token再用接口来请求一次。
流程8
实现流程1-7后,结合代理IP,就可以批量生成和使用了。
经实测,突破了之前的did使用上限,并且did可以被任何IP使用。
流程8是我们的控制变量,以该信息为判定标准,制定符合自己需求的采集策略。
关注公众号《Pythonlx》可获取群聊二维码。
 Google Chrome
Google Chrome  Windows 10
Windows 10 Mac OS X 10.15.7
Mac OS X 10.15.7